Exciting update!! Announcing new Anima LLM model, 100k context window!! Fully open source!


We released the new Anima open source 7B model, supporting an input window length of 100K! It’s based on LLama2, so available for commercial use!
With specifically curated long text question answering training data for the 100K input length, and a lot of memory optimizations, we enabled the LLama2 model to scale to 100K input length.
1. “Longer” is the future of AI
The intelligence level of large language models is growing rapidly. However, the amount of data they can process is very limited, with most models only up to 4k, and some extending to 32K.
Despite their strong logical reasoning abilities, these models fail to apply this capability to process large amounts of data.
True intelligence = Big data * Reasoning ability
Having only the powerful reasoning ability of the Large Language Model (LLM), without the capacity to process a substantial amount of information, it does not provide sufficient intelligence to solve real-world problems.
Common methods like Retrieval Augmented Generation (RAG) segment text, create vectorized indexes, and during inference, recall a portion of information input into the large language model. RAG can to some degree solve the issue of insufficient input length. However, it often encounters problems of insufficient or excessive recall(under-recall or over-recall). It is also often hard to determine the most reasonable way to segment the data.
In many practical data processing issues, the most valuable part is how to discover and select the most valuable portion from a sea of information. Many times, if the required information is accurately selected, it doesn’t take a high level of intelligence to solve the problem.
Fundamentally, RAG methods do not apply the highest intelligence of today’s AI, the large language model, to this crucial issue: information selection. Instead, it is an embedding model without a cross-attention mechanism, with quite limited capabilities.
More importantly, RAG assumes that information distribution is sparse. Key information only exists locally, which isn’t true in many real-world situations. Often, the most valuable information needs to be distilled/digested from the full text, and it would be insufficient if missing any single detail.
Improving the input window length of LLM is still the best way to apply the highest AI intelligence to the most valuable real-world data.
Simply put, for large models, “bigger” alone is not enough. We need both “bigger” and “longer”!
2. Why 100k is so hard?
For the training and inference of 100k, the biggest challenge is memory consumption.
Much of the memory size in the Transformer training process is proportional to the square of the input sequence length. When the input length reaches 100K, it’s quite a huge amount!
Some memory allocations are proportional to the input length multiplied by the total number of tokens (for the llama model, it’s 100K x 32000, which is also very large)
For instance, the line 330 of the original Llama2 implementation:
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) \
/ math.sqrt(self.head_dim)
The amount of memory needed for running this one line of code is:

So this one line of code allocates 596.04GB memory! It takes 8 H100 or A100 GPUs!

3. Memory optimization technologies in Anima 100k model
To optimize memory consumption during the training of models with 100K sequence length, a variety of cutting-edge technologies are used:
The Flashattention2 technology splits long sequences into blocks for calculation by implementing a special cuda kernel. This changes the O(sequence_length²) to O(sequence_length*block_size), reducing 596GB of memory down to 782MB:
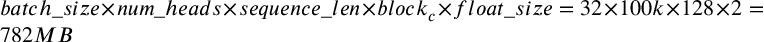
XEntropy can convert the memory allocation of sequence length * vocabulary size for logits computation into inplace, thereby saving half of the logits memory.
Paged 8bit Adamw can lower the memory usage of states and momentum in the adam optimizer from 32 bit to 8 bit by using 8 bit block-wise quantization, reducing it by four times.
LORA allows us not to optimize all parameters, but to use the product of a sparse matrix of LORA instead.
Input of 100K may run into various other Out of Memory (OOM) problems. We’ve made some other adjustments to the transformer code to solve the memory issues.
4. Training data for 100k
There are now many training datasets for large language models, but few are suitable for training with a length of 100K. Only training with long corpus and the next token prediction with Causal language modeling, the target output is in most of cases not really related to the entire input window. Only the local text impacts the target output mostly.
Such training data cannot train the model well to handle the entire 100K input data. The model really only needs local capabilities, not necessarily the capability to handle the entire 100K input.
We have selected some long-text question and answer data, for example the question and answer datasets in Narrative QA, where some input data is a very long book, possibly close to 100K tokens in length. The model needs to answer some questions based on the entire content of this book.
Such training data will force the model to enhance its attention capabilities for longer data in the prompt, the model must have the ability to understand the entire 100K input data and extract and process key information according to the prompt to answer the correct question. Training the model with such data can force the model to enhance its ability to handle 100K inputs.
As previously stated, we hope that training data is not based on the assumption of sparse information distribution, and the key information needed for the answer is best distributed throughout the whole input text. Ideally, each piece of local information needed should undergo a nonlinear mapping to arrive at an answer. Missing any detail is not enough.
We have carefully selected and constructed the Anima 100K training data from many datasets, and the length distribution also covers various lengths from 30K to 100K.
We have used this long-text question and answer data to fine-tune the Llama2 model. We assume that the basic model should already have good reasoning capabilities and knowledge encoded, and we are only enhancing the model’s capability to handle long texts while maintaining the model’s existing reasoning capabilities through this type of training.
5. Evaluation for 100k
There are many different evaluation datasets for LLMs, but almost none specifically designed for an input length of 100k. We constructed 3 datasets to evaluate several open-source long input LLMs that we could find, as well as the private LLM Claude 100k:
A. Longchat Topics Retrieval
Lmsys’s Longchat proposed a method of constructing long input evaluation dataset.
They construct many human-computer dialogue records between users and virtual assistants, each dialogue is about a certain topic. The task is to input a dialogue record into the model, and the model is required to find the topic of a specified dialogue.
The original data only had 40 dialogues and could not reach an input length of 100k. We expanded the dataset and increased the number of dialogues to 158 topics. Then, we constructed a new 100k dataset in a way similar to longchat.
The evaluation results are as follows:
Most of the topics can be accurately found by Claude 100k. But some outputs do not follow the original prompt, with some rewriting, thus the accuracy rate is 0.9.
The code to generate the review dataset can be found in the GitHub repo.
B. Longchat Lines Retrieval
The second evaluation set comes from another evaluation method proposed by Longchat.
They constructed many key-value pairs, each pair has a key and a value. The model is required to find the value corresponding to the specified key. We used the code used by longchat to construct a new 100k dataset.
The results are as follows:
The code to generate the dataset can be found in the GitHub repo as well.
C. ZeroSCROLLS NarrativeQA
The third review set used ZeroSCROLLS’ NarrativeQA long text question and answer because it’s the only one among various zeroscroll datasets that include very long input.
We specifically checked that the data in the dataset does not exist in Anima 100k’s training data. This can ensure that the review is objective and there is no leaking problem.
According to the NarrativeQA Paper, the answer result uses a F1 score similar to Squad.
The evaluation results are as follows:
As can be seen, our training of Anima 100k’s long input processing ability has indeed greatly improved. Of course, there is still a gap with Claude due to the model size.
6. Open source the model
The open-source model can be found on huggingface (lyogavin/Anima-7B-100K).
For the code for training, evaluation, and inference, please visit our github repo (https://github.com/lyogavin/Anima/anima_100k).
7. Who is the murderer?
With the capacity of procssing 100k input data, we can do many interesting things now.
For example, we can input an entire novel into the model and ask it to answer some questions.
We input the entire novel “Eight Million Ways to Die” by the famous hard-boiled detective novelist Lawrence Block into the model and asked it a few questions:
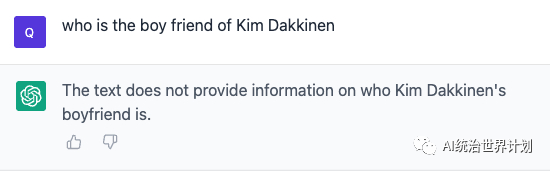
Who is the real murderer of Kim? Who is Kim’s boyfriend?

To create suspense, detective novels often have to give all kinds of misleading information to mislead the reader, then perform several big twists at the end. The model must be able to fully comprehend the whole content of the book in order not to be misled and find the real answer.
The length of this book slightly exceeds 100k, so we randomly cut out a part of the middle content. Then, all remaining content close to 100k is input into Anima 100K.
Let’s see if Anima 100K can understand who the murderer is in this book:
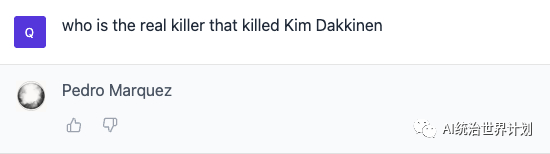
It got it right! 👍
Now let’s look at another question:
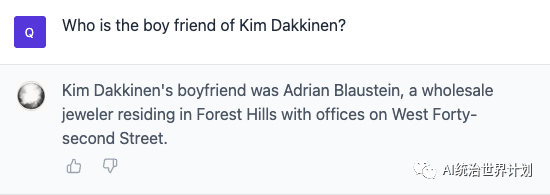
This question was also correctly answered.
It appears that Anima 100K has the ability to understand and analyze long-form content.
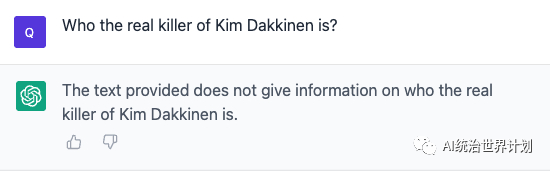
Now, let’s see how RAG + GPT4 performs:
Since the input window cannot exceed 8K, we indexed the text based on RAG, then selected the top 3 inputs based on the question, and prompted them to GPT4, the answers are as follows:
We will continue to open-source the latest and coolest papers and algorithms to contribute to the open-source community. Please follow us for the latest updates.
If you like our content, please clap, share, and feel free to comment and communicate with us if you have any questions or suggestions!