How AI Text Generation Models Are Reshaping Customer Support at Airbnb


How AI Text Generation Models Are Reshaping Customer Support at Airbnb
Leveraging text generation models to build more effective, scalable customer support products.

Gavin Li, Mia Zhao and Zhenyu Zhao
One of the fastest-growing areas in modern Artificial Intelligence (AI) is AI text generation models. As the name suggests, these models generate natural language. Previously, most industrial natural language processing (NLP) models were classifiers, or what might be called discriminative models in machine learning (ML) literature. However, in recent years, generative models based on large-scale language models are rapidly gaining traction and fundamentally changing how ML problems are formulated. Generative models can now obtain some domain knowledge through large-scale pre-training and then produce high-quality text — for instance answering questions or paraphrasing a piece of content.
At Airbnb, we’ve heavily invested in AI text generation models in our community support (CS) products, which has enabled many new capabilities and use cases. This article will discuss three of these use cases in detail. However, first let’s talk about some of the beneficial traits of text generation models that make it a good fit for our products.
About Text Generation Models
Applying AI models in large-scale industrial applications like Airbnb customer support is not an easy challenge. Real-life applications have many long-tail corner cases, can be hard to scale, and often become costly to label the training data. There are several traits of text generation models that address these challenges and make this option particularly valuable.
Encoding Knowledge
The first attractive trait is the capability to encode domain knowledge into the language models. As illustrated by Petroni et al. (2019), we can encode domain knowledge through large-scale pre-training and transfer learning. In traditional ML paradigms, input matters a lot. The model is just a transformation function from the input to the output. The model training focuses mainly on preparing input, feature engineering, and training labels. While for generative models, the key is the knowledge encoding. How well we can design the pre-training and training to encode high-quality knowledge into the model — and how well we design prompts to induce this knowledge — is far more critical. This fundamentally changes how we solve traditional problems like classifications, rankings, candidate generations, etc.
Over the past several years, we have accumulated massive amounts of records of our human agents offering help to our guests and hosts at Airbnb. We’ve then used this data to design large-scale pre-training and training to encode knowledge about solving users’ travel problems. At inference time, we’ve designed prompt input to generate answers based directly on the encoded human knowledge. This approach produced significantly better results compared to traditional classification paradigms. A/B testing showed significant business metric improvement as well as significantly better user experience.
Unsupervised Learning
The second trait of the text generation model we’ve found attractive is its “unsupervised” nature. Large-scale industrial use cases like Airbnb often have large amounts of user data. How to mine helpful information and knowledge to train models becomes a challenge. First, labeling large amounts of data by human effort is very costly, significantly limiting the training data scale we could use. Second, designing good labeling guidelines and a comprehensive label taxonomy of user issues and intents is challenging because real-life problems often have long-tail distribution and lots of nuanced corner cases. It doesn’t scale to rely on human effort to exhaust all the possible user intent definitions.
The unsupervised nature of the text generation model allows us to train models without largely labeling the data. In the pre-training, in order to learn how to predict the target labels, the model is forced to first gain a certain understanding about the problem taxonomy. Essentially the model is doing some data labeling design for us internally and implicitly. This solves the scalability issues when it comes to intent taxonomy design and cost of labeling, and therefore opens up many new opportunities. We’ll see some examples of this when we dive into use cases later in this post.
More Natural and Productive Language Models
Finally, text generation models transcend the traditional boundaries of ML problem formulations Over the past few years, researchers have realized that the extra dense layers in autoencoding models may be unnatural, counterproductive, and restrictive. In fact, all of the typical machine learning tasks and problem formulations can be viewed as different manifestations of the single, unifying problem of language modeling. A classification can be formatted as a type of language model where the output text is the literal string representation of the classes.
In order to make the language model unification effective, a new but essential role is introduced: the prompt. A prompt is a short piece of textual instruction that informs the model of the task at hand and sets the expectation for what the format and content of the output should be. Along with the prompt, additional natural language annotations, or hints, are also highly beneficial in further contextualizing the ML problem as a language generation task. The incorporation of prompts has been demonstrated to significantly improve the quality of language models on a variety of tasks. The figure below illustrates the anatomy of a high-quality input text for universal generative modeling.
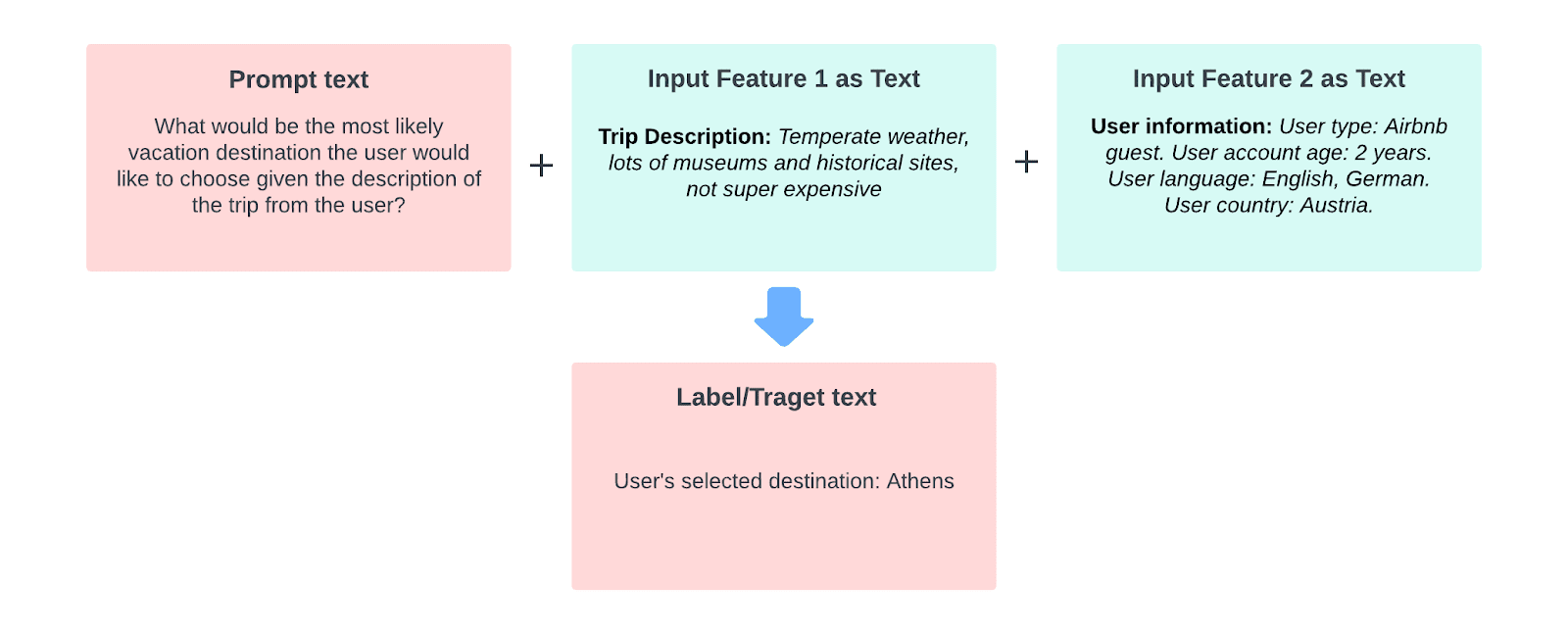
Now, let’s dive into a few ways that text generation models have been applied within Airbnb’s Community Support products. We’ll explore three use cases — content recommendation, real-time agent assistance, and chatbot paraphrasing.
Content Recommendation Model
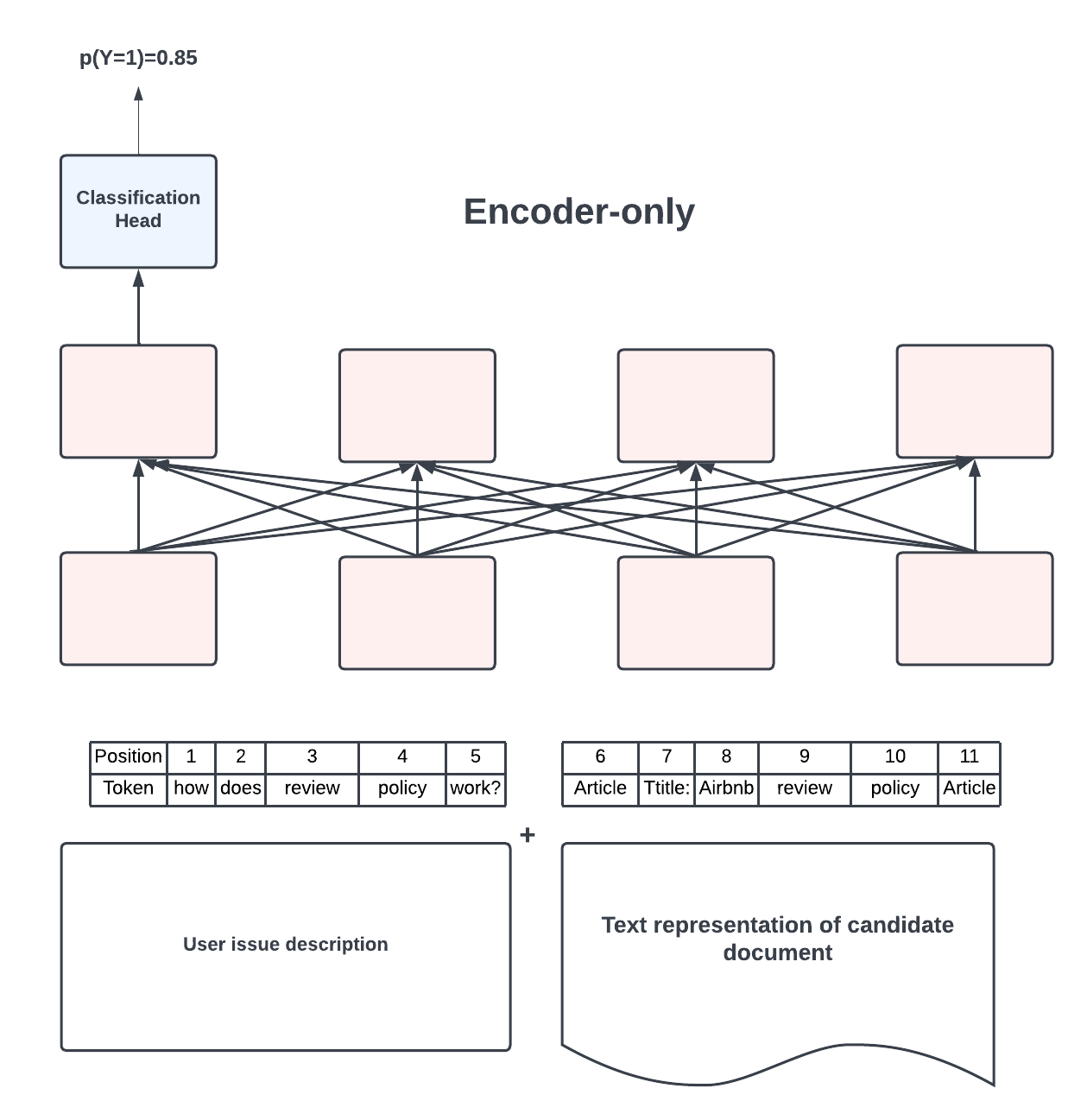
Our content recommendation workflow, powering both Airbnb’s Help Center search and the support content recommendation in our Helpbot, utilizes pointwise ranking to determine the order of the documents users receive, as shown in Figure 2.1. This pointwise ranker takes the textual representation of two pieces of input — the current user’s issue description and the candidate document, in the form of its title, summary, and keywords. It then computes a relevance score between the description and the document, which is used for ranking. Prior to 2022, this pointwise ranker had been implemented using the XLMRoBERTa, however we’ll see shortly why we’ve switched to the MT5 model.
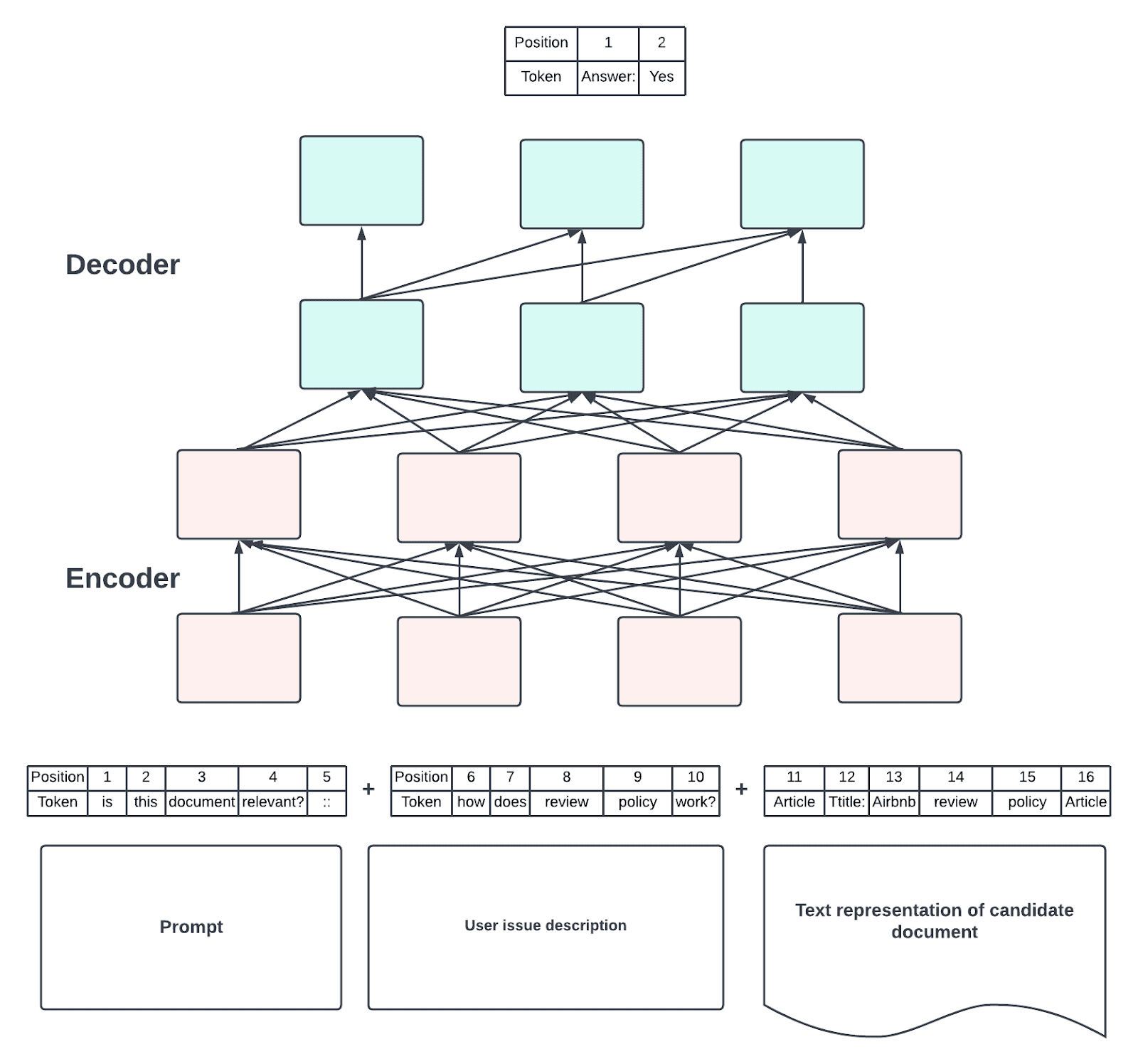
Following the design decision to introduce prompts, we transformed the classic binary classification problem into a prompt-based language generation problem. The input is still derived from both the issue description and the candidate document’s textual representation. However, we contextualize the input by prepending a prompt to the description that informs the model that we expect a binary answer, either “Yes” or “No”, of whether the document would be helpful in resolving the issue. We also added annotations to provide extra hints to the intended roles of the various parts of the input text, as illustrated in the figure below. To enable personalization, we expanded the issue description input with textual representations of the user and their reservation information.
We fine-tuned the MT5 model on the task described above. In order to evaluate the quality of the generative classifier, we used production traffic data sampled from the same distribution as the training data. The generative model demonstrated significant improvements in the key performance metric for support document ranking, as illustrated in the table below.
In addition, we also tested the generative model in an online A/B experiment, integrating the model into Airbnb’s Help Center, which has millions of active users. The successful experimentation results led to the same conclusion — the generative model recommends documents with significantly higher relevance in comparison with the classification-based baseline model.
‘Real-Time Agent Assistant’ Model
Equipping agents with the right contextual knowledge and powerful tools leads to better experiences for our customers. So we provide our agents with just-in-time guidance, which directs them to the correct answers consistently and helps them resolve user issues efficiently.
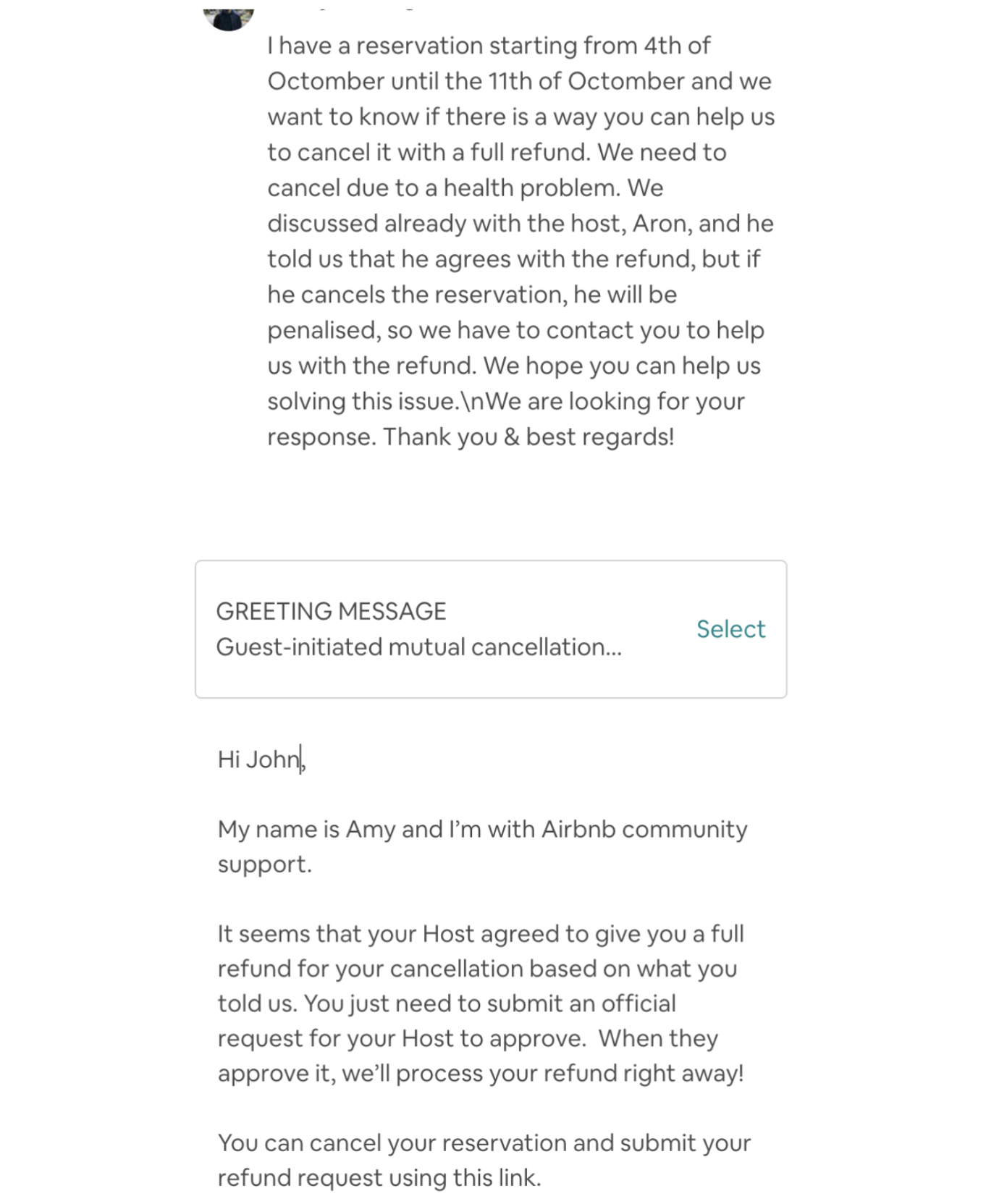
For example, through agent-user conversations, suggested templates are displayed to assist agents in problem solving. To make sure our suggestions are enforced within CS policy, suggestion templates are gated by a combination of API checks and model intent checks. This model needs to answer questions to capture user intents such as:
-
Is this message about a cancellation?
-
What cancellation reason did this user mention?
-
Is this user canceling due to a COVID sickness?
-
Did this user accidentally book a reservation?
In order to support many granular intent checks, we developed a mastermind Question-Answering (QA) model, aiming to help answer all related questions. This QA model was developed using the generative model architecture mentioned above. We concatenate multiple rounds of user-agent conversations to leverage chat history as input text and then ask the prompt we care about at the point in time of serving.
Prompts are naturally aligned with the same questions we ask humans to annotate. Slightly different prompts would result in different answers as shown below. Based on the model’s answer, relevant templates are then recommended to agents.
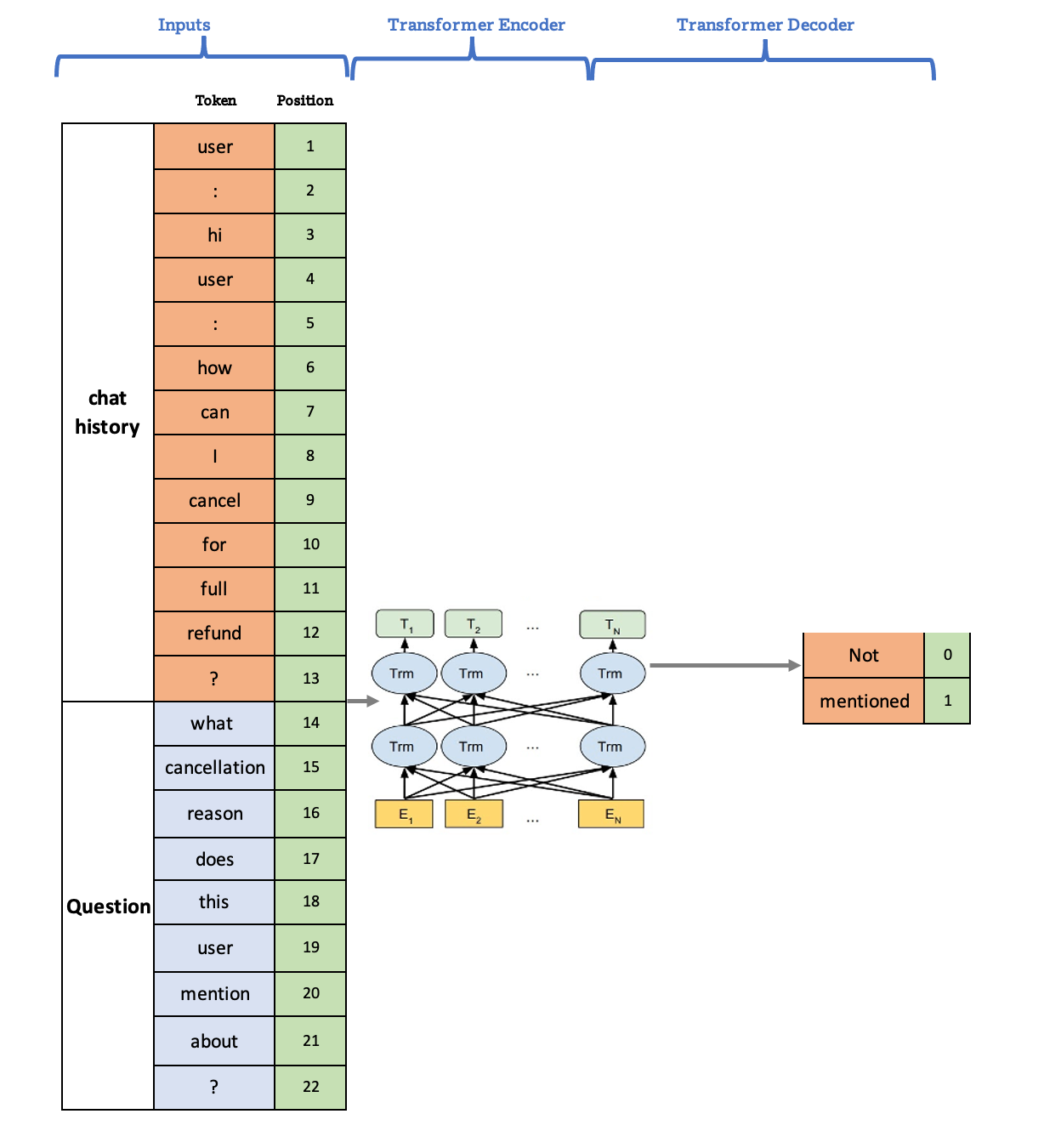
We leveraged backbone models such as t5-base and Narrativa and did experimentations on various training dataset compositions including annotation-based data and logging-based data with additional post-processing. Annotation datasets usually have higher precision, lower coverage, and more consistent noise, while logging datasets have lower precision, higher case coverage, and more random noises. We found that combining these two datasets together yielded the best performance.
Due to the large size of the parameters, we leverage a library, called DeepSpeed, to train the generative model using multi GPU cores. DeepSpeed helps to speed up the training process from weeks to days. That being said, it typically requires longer for hyperparameter tunings. Therefore, experiments are required with smaller datasets to get a better direction on parameter settings. In production, online testing with real CS ambassadors showed a large engagement rate improvement.
Paraphrase Model in Chatbot
Accurate intent detection, slot filling, and effective solutions are not sufficient for building a successful AI chatbot. Users often choose not to engage with the chatbot, no matter how good the ML model is. Users want to solve problems quickly, so they are constantly trying to assess if the bot is understanding their problem and if it will resolve the issue faster than a human agent. Building a paraphrase model, which first rephrases the problem a user describes, can give users some confidence and confirm that the bot’s understanding is correct. This has significantly improved our bot’s engagement rate. Below is an example of our chatbot automatically paraphrasing the user’s description.
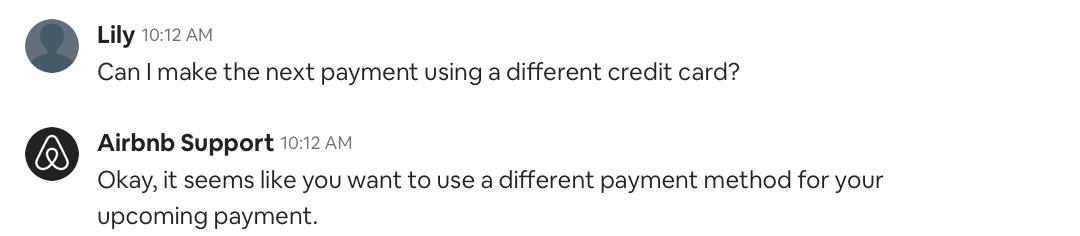
This method of paraphrasing a user’s problem is used often by human customer support agents. The most common pattern of this is “I understand that you…”. For example, if the user asks if they can cancel the reservation for free, the agent will reply with, “I understand that you want to cancel and would like to know if we can refund the payment in full.” We built a simple template to extract all the conversations where an agent’s reply starts with that key phrase. Because we have many years of agent-user communication data, this simple heuristic gives us millions of training labels for free.
We tested popular sequence-to-sequence transformer model backbones like BART, PEGASUS, T5, etc, and autoregressive models like GPT2, etc. For our use case, the T5 model produced the best performance.
As found by Huang et al. (2020), one of the most common issues of the text generation model is that it tends to generate bland, generic, uninformative replies. This was also the major challenge we faced.
For example, the model outputs the same reply for many different inputs: “I understand that you have some issues with your reservation.” Though correct, this is too generic to be useful.
We tried several different solutions. First, we tried to build a backward model to predict P(Source|target), as introduced by Zhang et al. (2020), and use it as a reranking model to filter out results that were too generic. Second, we tried to use some rule-based or model-based filters.
In the end, we found the best solution was to tune the training data. To do this, we ran text clustering on the training target data based on pre-trained similarity models from Sentence-Transformers. As seen in the table below, the training data contained too many generic meaningless replies, which caused the model to do the same in its output.
We labeled all clusters that are too generic and used Sentence-Transformers to filter them out from the training data. This approach worked significantly better and gave us a high-quality model to put into production.
Conclusion
With the fast growth of large-scale pre-training-based transformer models, the text generation models can now encode domain knowledge. This not only allows them to utilize the application data better, but allows us to train models in an unsupervised way that helps scale data labeling. This enables many innovative ways to tackle common challenges in building AI products. As demonstrated in the three use cases detailed in this post — content ranking, real-time agent assistance, and chatbot paraphrasing — the text generation models improve our user experiences effectively in customer support scenarios. We believe that text generation models are a crucial new direction in the NLP domain. They help Airbnb’s guests and hosts solve their issues more swiftly and assist Support Ambassadors in achieving better efficiency and a higher resolution of the issues at hand. We look forward to continuing to invest actively in this area.
Acknowledgments
Thank you Weiping Pen, Xin Liu, Mukund Narasimhan, Joy Zhang, Tina Su, Andy Yasutake for reviewing and polishing the blog post content and all the great suggestions. Thank you Joy Zhang, Tina Su, Andy Yasutake for their leadership support! Thank you Elaine Liu for building the paraphrase end-to-end product, running the experiments, and launching. Thank you to our close PM partners, Cassie Cao and Jerry Hong, for their PM expertise. This work could not have happened without their efforts.
Interested in working at Airbnb? Check out these open roles.