Open-Source SORA Has Arrived! Training Your Own SORA Model!


To date, the open-source model that comes closest to SORA is Latte, which employs the same Vision Transformer architecture as SORA. What exactly makes the Vision Transformer outstanding, and how does it differ from previous methods?
Latte has not open-sourced its text-to-video training code. We have replicated the text-to-video training code from the paper and made it available for anyone to use, to train their own SORA alternative model. How effective was our own training? The details will be discussed below.
01
From 3D U-Net to Vision Transformer
Image generation has matured significantly, with the UNet model structure being the most commonly used for image generation:
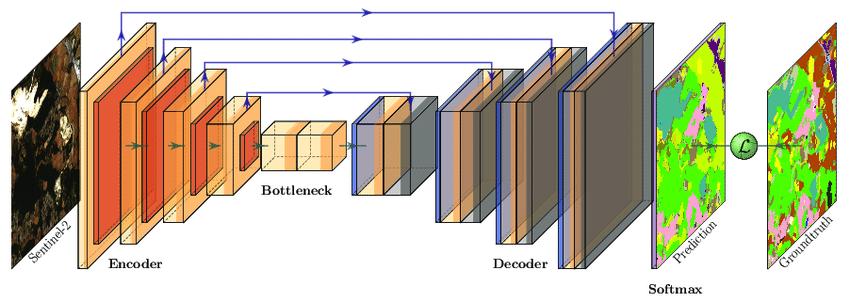
U-Net is a network structure that first compresses and shrinks the input image, and then gradually decodes and enlarges it, shaped like a U. Early video generation models extended the U-Net structure to support video.
Going from image to video is actually quite simple — it’s just extending the 2D height x width to 3D by adding a time dimension:

Early video generation network structures simply expanded the two-dimensional UNet into a three-dimensional UNet by incorporating a time dimension.
By integrating a transformer within this time dimension, the model learns what the image should look like at a given time point, for instance, at the nth frame.
Originally, given a prompt, it generates one image. A 3D UNet, given a prompt, generates 16 images.
The issue with the 3D UNet structure is that the transformer can only function within the UNet and cannot see the whole picture. This often results in poor consistency between consecutive frames in a video, and the model also lacks sufficient learning capacity for larger movements and motions.
If you’re still confused about the network structures of 2D-UNet and 3D-UNet, it’s not that complicated. There are really not that much logic behind the network design, just remember one of the most important things about deep learning: “Just Add More Layers”!
02
Vision Transformer
The transformer in the 3D UNet only works inside the UNet and cannot see the whole picture. Vision Transformer, on the other hand, allows transformers to globally dominate video generation.
The modeling method of Vision Transformer is more similar to that of language models: we can directly consider a video as a sequence. Each data block in the sequence could be a small piece of image.
Similar to how a language model tokenizer works, videos can be encoded into a sequence of tokens.
Once the sequence is established, we can directly apply Transformers.
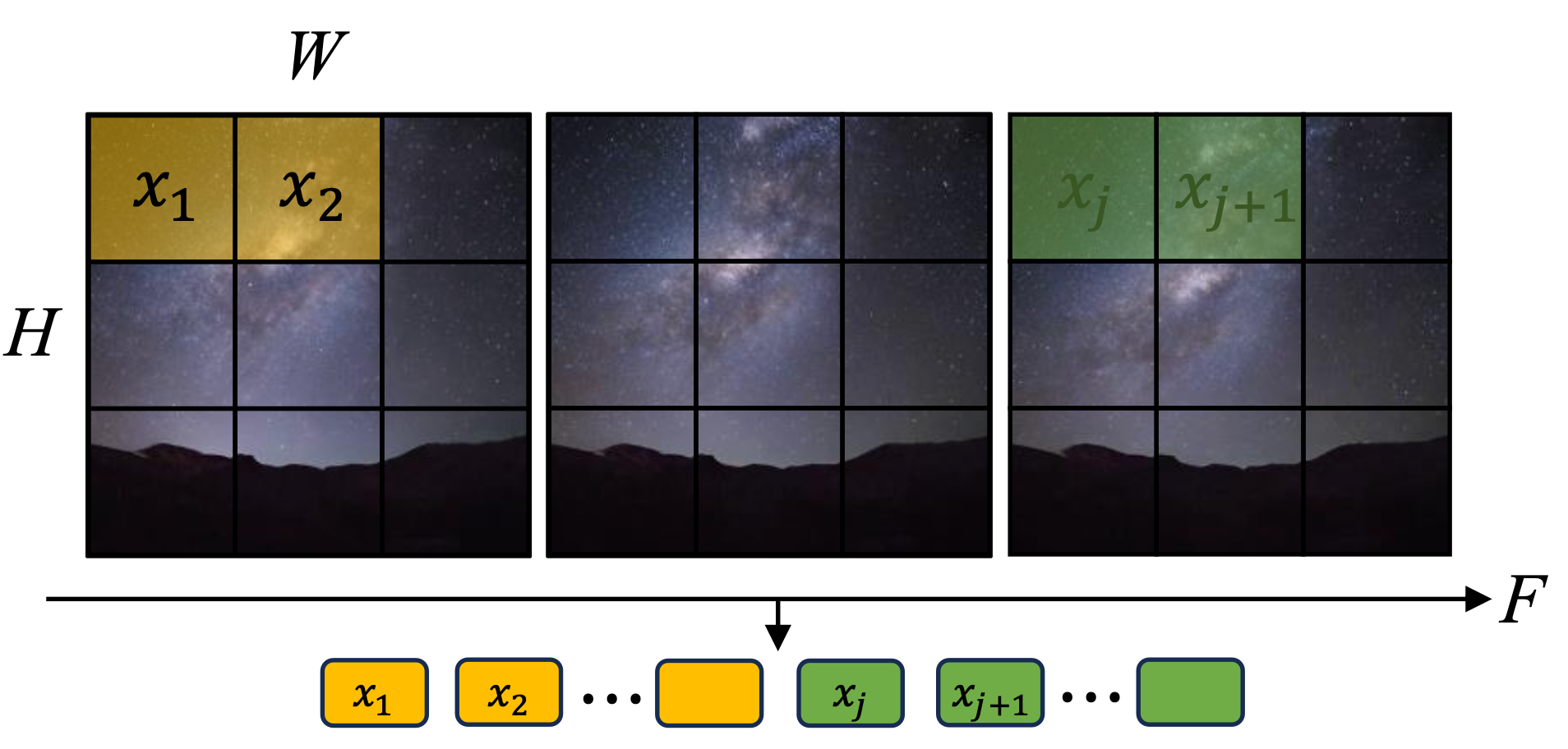
Mathematically, Vision Transformer is quite straightforward; it applies similar mechanism as in language model: transforming a video into a token sequence, and then applying numerous layers of transformers aggressively.
This simple design aligns well with OpenAI’s style — simple and brute-force.
OpenAI actually does not favor mathematically complex or fancy approaches. In the early days, OpenAI’s GPT-2 was somewhat looked down upon compared to various fancy models like T5 and DeBerta, for being too simple and crude.
However, relatively simple and operable model structures can actually make it easier for models to scale stably to larger amounts of training data. OpenAI chose not to compete in model structures but to compete in data.
And then, it’s about piling up petabytes of data and tens of thousands of GPUs.
The only difference between me and OpenAI is just tens of thousands of GPUs.

Compared to 3D UNet, Vision Transformer allows the model to focus more on learning the patterns of motion imagery.
Greater movement amplitude and longer video lengths have always been challenges for video generation models. Vision Transformer significantly enhances capabilities in these aspects.
03
Training Your Open-Source SORA Alternative, Latte
Latte employs the video slicing sequence and Vision Transformer method mentioned earlier. This aligns with what is generally understood about SORA.
Latte has not open-sourced the text to video model training code. We have replicated the paper’s training code for everyone here: https://github.com/lyogavin/train_your_own_sora, please feel free to use it.
Training requires only three steps:
-
Download and train the model, install the environment
-
Prepare training videos
-
Run the training:
./run_img_t2v_train.sh
For more details, see the github repo.
We have also made some improvements to the training process:
-
Added support for gradient accumulation to reduce memory requirements
-
Included validation samples during training to help verify the training process
-
Added support for wandb
-
Included support for classifier-free guidance training.
04
Model Performance
The official video for Latte is as follows:
The official video appears to perform well, especially in terms of significant motion.
We have also compared various models in our own training data. Latte indeed performs well, but it is not the best-performing model. There are other open-source models with better performance.
Although Latte employs an effective network structure, its larger scale means that, according to the famous scaling law, it requires much more in terms of the quantity and quality of training data.
The capability of a video model heavily relies on the performance of its pretrained image model. It seems that the pretrained base image model used by Latte also needs to be strengthened.
We will continue to share other models with better performance in the future, so make sure you follow my blog.
05
Hardware Requirements
Due to its large scale, training Latte requires an A100 or H100 with 80GB of memory.
We will continue to share the latest and coolest AI model algorithms and open-source technologies.
Leave your comments below and make sure to follow this blog!